The Procurement Inversion Takes a Paper Cut
MiniMax M3 extends the open-weight procurement default at frontier coding, but on harder terms — non-MIT license, datacenter hardware floor, and DeepSeek wins cache pricing 17x over.
MiniMax M3 extends the open-weight procurement default at frontier coding, but on harder terms — non-MIT license, datacenter hardware floor, and DeepSeek wins cache pricing 17x over.
iOS 27 Beta 1 contains the full third-party AI Extensions framework — Settings panel, App Store category, entitlements, four system surfaces — with the runtime gated off. None of the four reasons Apple deferred it are technical.
Microsoft is the first hyperscaler to ship GA eval, GA governance, an open cross-vendor spec, and a flagship Big-4 deployment in one release window. AWS and Google have 90 days to respond before RFP season closes.
EO 14409 set up a voluntary AI framework on June 2. Eleven days later, Commerce used existing export-control authority to force Anthropic to disable Fable 5 and Mythos 5 worldwide. The two tracks now run in parallel.
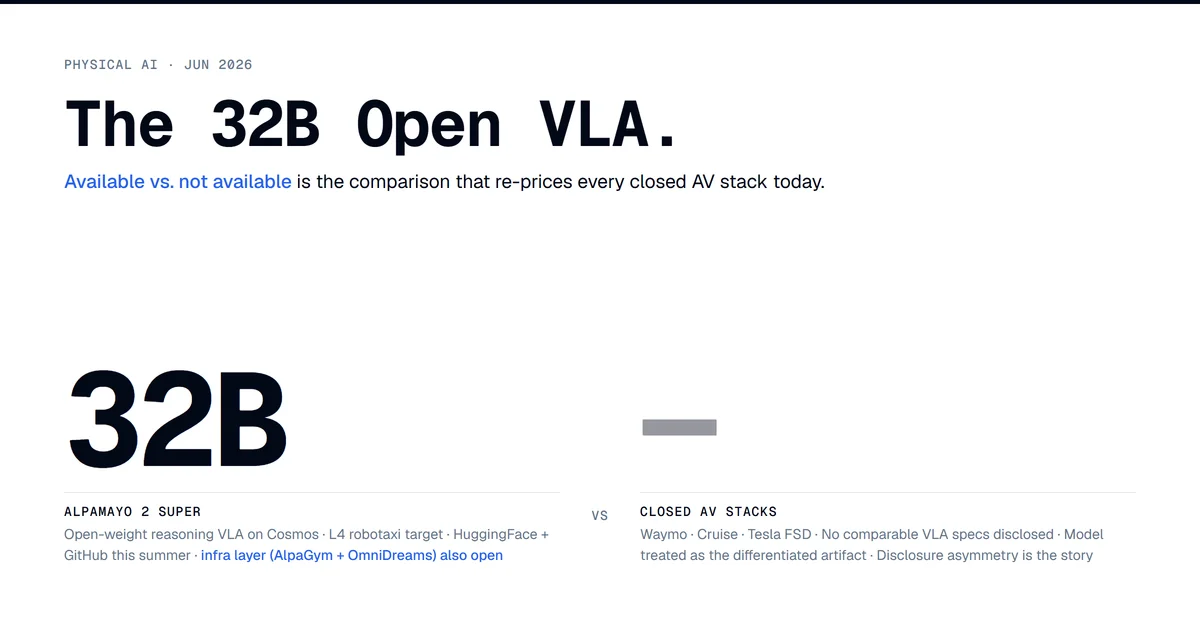
NVIDIA open-weighted Cosmos 3 and a 32B reasoning VLA for L4 robotaxis. The chip vendor just open-sourced the model layer above its own GPUs.
Antigravity 2.0, MS Agent Framework 1.0, and AWS AgentCore Runtime now form a commodity baseline. The harness around them is still the buyer's problem, and that gap is where the sticker shock is coming from.
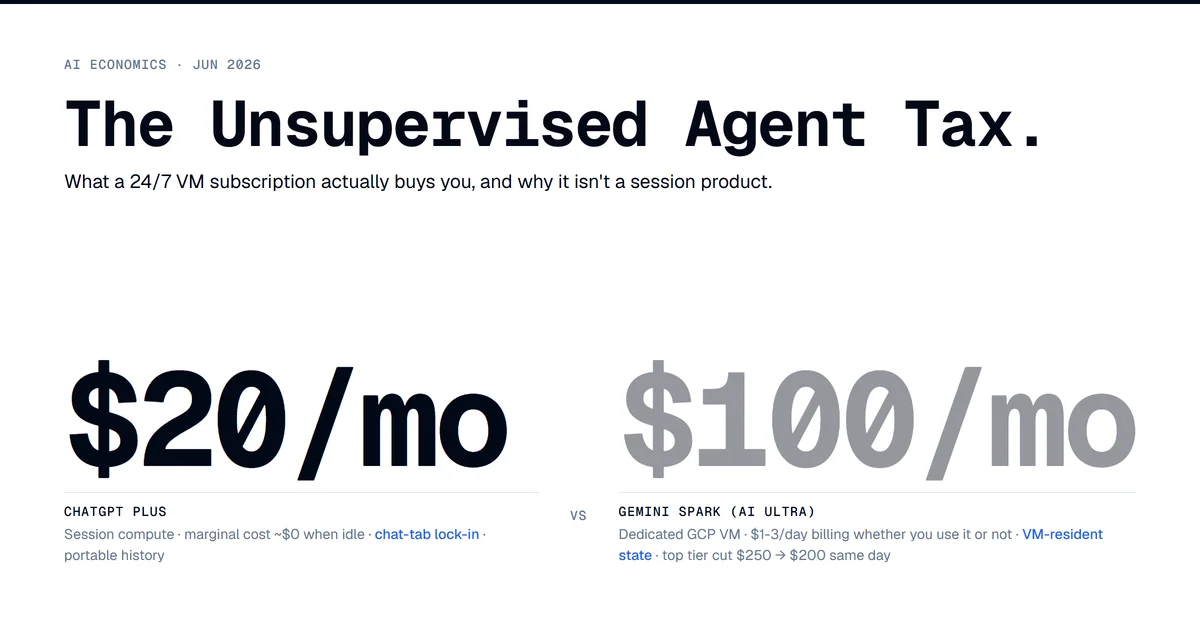
Gemini Spark runs on dedicated GCP VMs whether you use it or not. The $100 AI Ultra tier prices the always-on VM, not session compute.
Anthropic shipped Opus 4.8, a $65B Series H, and a Mythos GA commitment in one week. Three weeks later, ENISA joined Glasswing as the first foreign agency.
Secure multi-agent handoffs by replacing natural language prompts with Pydantic schemas and deterministic contracts to prevent data leakage and system failure.
The Arscontexta Skill Graph solves O(n) context bloat in AI agents by replacing massive system prompts with a navigable SKILLS.md folder structure.
Situational Awareness LP just tripled its book to $13.7B and FinX parsed every position before the document had been on EDGAR for an hour. The pipeline that surfaces those filings the minute they land is ~250 lines of Python, one JSON registry, and a Telegram bot. $0 per month. Point your agent at this article.
Five Reddit posts, every major vendor's framework release, and Uber's 1,500-agent data point all converged on one diagnosis: the harness is the constraint, not the LLM.
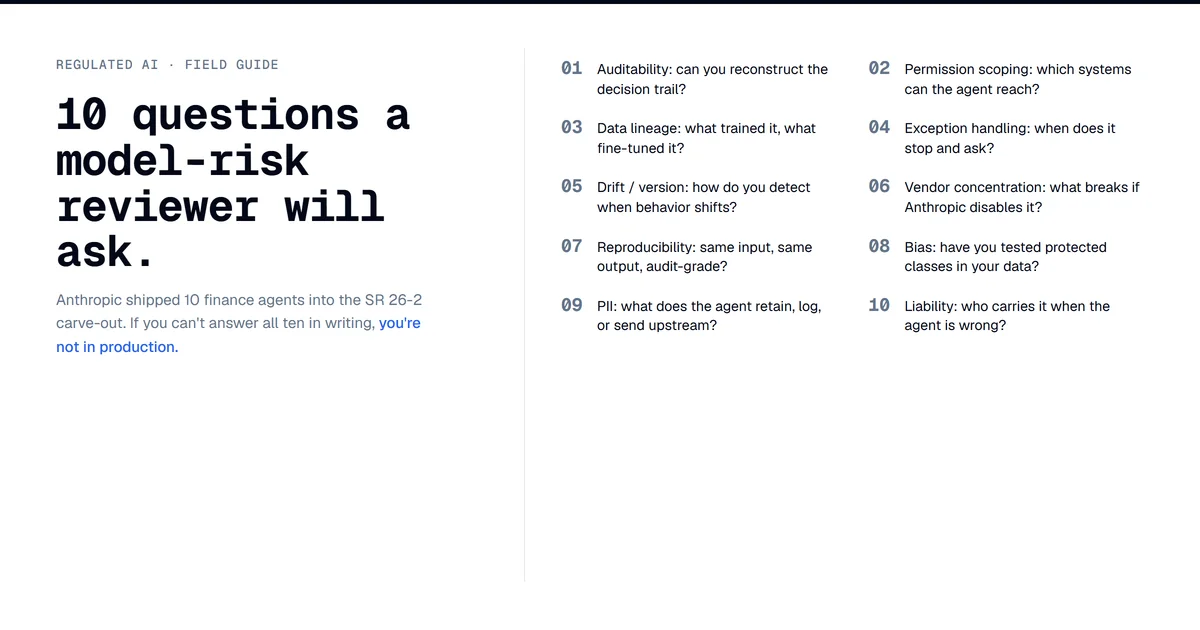
Anthropic shipped 10 finance agents 18 days after SR 26-2 carved generative and agentic AI out of model risk. Here is the Day 1 diligence checklist.
Anthropic crossed $30B ARR while OpenAI sat at $24B. The model layer bifurcated by buyer surface, and Bain's $2T sector revenue math got harder, not easier.
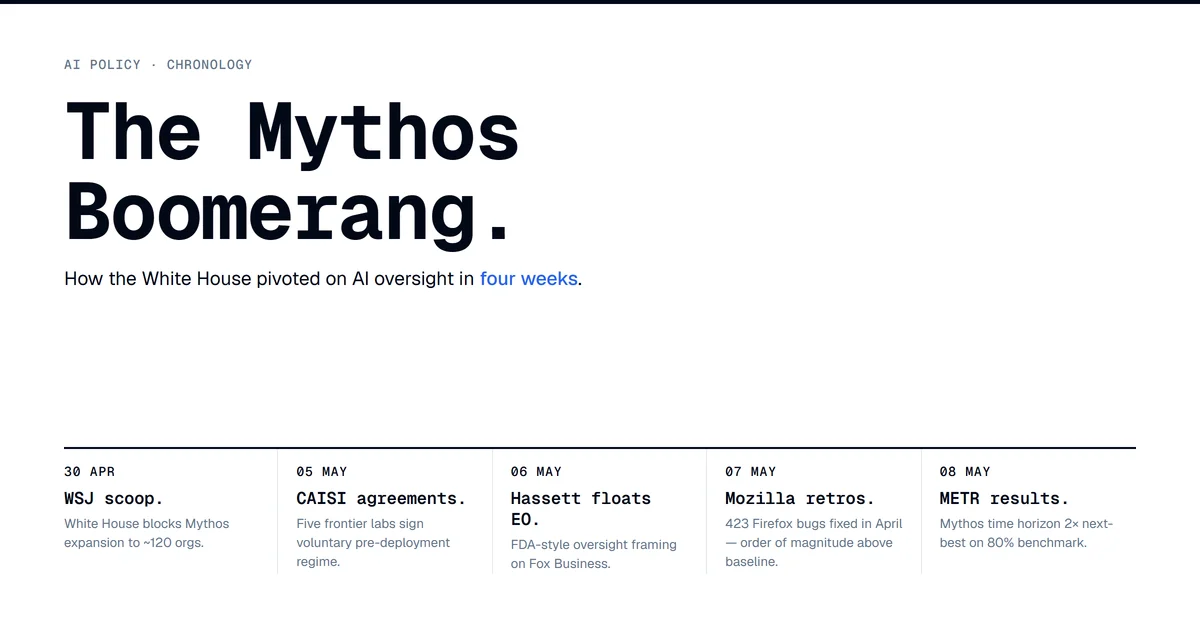
Anthropic's Mythos gating fight became federal AI policy in four weeks. Five labs, CAISI, and an FDA-style executive order changed the regime.
DeepSeek V4-Pro shipped MIT-licensed at 1.6T parameters while Anthropic Mythos sits behind White House gating, and enterprise procurement just walked through the open-weight door.
Meta, Microsoft, Alphabet, and Amazon all spent like hyperscalers in Q1 2026. The market priced one of them as a thesis bet. Here's why.
A close read of the MIT EEG paper, the Microsoft survey, and the METR developer study — what the evidence actually supports about AI agents and human cognition.
The White House blocked Anthropic's plan to expand Mythos access on April 30. Six days earlier, DeepSeek shipped 1.6T parameter weights for vulnerability discovery on Hugging Face.
A research team reverse-engineered Claude Code and found that 1.6% is AI logic and 98.4% is infrastructure. The paper maps every design decision agent builders make implicitly.
A formal proof shows that increasing transformer expressivity leads to strictly worse financial predictions under MSE loss. PatchTST lost to a linear model on 92% of test windows.
Stanford's 2026 AI Index contradicts consensus narratives. The US ranks 24th in AI adoption, benchmarks predict nothing about reliability, and transparency is collapsing.
AI coding tools create a pipeline time bomb. Junior devs develop a 17% comprehension gap while senior engineers drown in 98% more PR reviews.
A 25% tariff on AI chips with a 100MW exemption floor favors hyperscalers. Startups face 50-75% cost increases while domestic production is years away.
Tennessee SB 1493 makes chatbot building a Class A felony while the White House pushes deregulation. 78 AI bills across 27 states and zero federal preemption.
AI layoffs in Q1 2026 targeted middle management, not entry-level workers. Oracle, Amazon, Block, and Snap cut managers to fund AI infrastructure.
You can't hand a song to an LLM and expect it to understand production. I built a decomposition pipeline that extracts 40+ parameters per stem, and the pattern applies far beyond music.
A shoe company rebranded as NewBird AI, surged 600%, and revealed exactly where we are in the AI hype cycle.
Everyone's building AI second brains with Claude Code and Obsidian. Here's what actually works, what breaks, and why I built two Obsidian plugins before the trend existed.
GLM-5.1 topped SWE-Bench Pro under MIT license. Gemma 4 shipped edge variants under Apache 2.0. Open source model parity is here — with caveats builders need to understand.
Amazon, Meta, Google, and Microsoft are spending $650B on AI infrastructure. Goldman Sachs says the GDP contribution is basically zero. Here's what the data actually shows.
The technical companion to Foliome's release. How the agent builds its own bank integrations, orchestrates parallel sync with MFA routing, recovers from errors without human intervention, and serves a dashboard from your local machine.
I haven't logged into a bank app in three months. An open-source financial operating system where your AI agent syncs your banks, classifies spending, and gives you complete financial intelligence. Everything local. Everything yours.
Financial markets are reflexive. AI models degrade the patterns they exploit. The CFA Institute says augmentation, not automation.
OpenAI is betting on agents, Anthropic on coding, Google on multimodal. Here's the evidence, the strategy layer, and what to do if you're building in between.
DPO fine-tuning a 1.2B model with LoRA improved style but degraded reasoning after 400 samples — accuracy dropped from 39/40 to 34/40, and the base model won.
How I route between two LFM2.5-1.2B models on a Raspberry Pi 5 — when to use Instruct, when to use Thinking, and why user-controlled toggles beat automatic detection.
Airbnb doesn't run OpenAI in production. Cursor built its own Tab model. The shift to fine-tuned small models is real — here's the decision framework for builders.
Building agents with a single shell execution tool reduces formatting errors and improves autonomy by leveraging LLM training data instead of brittle JSON schemas.
M5 Max hardware enables 120B parameter models to run locally at 65.8 tokens per second, shifting developer focus from public open-source projects to private, hyper-personalized dark tools for maximum leverage.
Every solo builder is sharing their AI stack. Nobody explains why they chose it. The difference between a stack and a dependency trap.
WEF predicted 85M AI job losses by 2025. Actual US figure: 200K-300K. Oil, tariffs, and DOGE explain more than AI does.
AI displaced 200K-300K jobs while employment grew 2.5%. The opportunity isn't learning to code. It's solving a $1,000 problem in your domain with AI tools.
Build a secure text-to-data portal using Snowflake Cortex and Llama 3.1 to translate English into Pandas while maintaining a strict Python sandbox.
Reduce Gemini agent shortcuts and memory loss by replacing flat tool lists with a file-system Skill Graph for structured, stateful workflows.
Anthropic's own labor data shows AI isn't eliminating white-collar jobs yet — it's quietly shrinking entry-level hiring. Here's what that means if you're making the move into tech right now.
Recursive Language Models replace massive context windows with a programmatic loop, letting small local models process infinitely long prompts.
I took the voice transcription pipeline out of my note app and shipped it as an Obsidian plugin. No platform. No local server. Just the slice that worked.
Why single prompt files fail for AI agents—and how failure-driven codification built a 108,000-line C# system with 19 specialized agents.
How to manage a 24% knowledge-to-code ratio using a 3-tier context architecture—Hot, Warm, and Cold storage for AI agents.
How a 24% knowledge-to-code ratio prevents AI hallucinations and architectural rot in 100k+ line repositories.
Stop using 2,000-word system prompts. Learn how Tiered Context Architecture, Style Injection, and the Observer Pattern optimize AI agent performance and cost.
An evaluation of the OpenClaw gateway, the 'soul.md' ecosystem, and why separating Skills from Souls is the key to reliable agents.
RLMs let small models handle inputs 100x beyond their context window by storing prompts in a REPL and recursively processing slices. Here's how it works.
Parameter counts are a vanity metric. How to read LLM architectures, what active parameters mean for your hardware, and the benchmarks that actually matter.
A strategic blueprint for the modern AI stack: moving from simple LLM wrappers to model routing, multi-agent orchestration, and local-first memory.
ChatGPT Ads target conversation context, not keywords. Here's what OpenAI confirmed, what's speculated, and how GEO content prepares you for both.
Obsidian doesn't have custom blocks, so I faked it with a code fence, a hidden div, and two features that actually make it useful.
Large context windows introduce massive KV cache costs and latency. GraphRAG provides better retrieval accuracy for complex datasets at a fraction of the compute expense.
An RTX 5090 cluster breaks even against DeepSeek API costs at 450M tokens of inference, providing a 14-month ROI for high-volume developers.
Distill DeepSeek-R1 reasoning into small models for $0.50 using logit-based probability mapping. A high-signal alternative to standard fine-tuning.
Comparing Qwen 3.5-2B and Liquid LFM2.5-1.2B on Raspberry Pi 5: benchmarks for GPQA intelligence, RAM usage, and time-to-first-token latency.
Voice transcription in 2026: who ships what (Monologue, Wispr Flow, Hey Lemon), what builders use (Whisper, AssemblyAI), and why fragmentation and lock-in are the real problem.
How to build a private, fully local voice assistant on Raspberry Pi 5 using Python and Whisper for on-device speech processing and LLM inference.
Actual traffic and conversion data for Product Hunt, Hacker News, and AppSumo — including the 10% featured rate and specific ROI math for indie makers.
Optimizing llama.cpp for LFM2.5-1.2B on a Raspberry Pi 5. Recommended settings for quantization, threads, and KV cache to maximize local LLM performance.
Build a private AI voice assistant on Raspberry Pi 5 with Whisper and Liquid LFM2.5. Includes memory budgets, hardware setup, and Python code.
Embedding deep research in a note app with Exa.ai. I built a 5-phase enrichment pipeline, then simplified to Exa with a light review step.
AI search engines don't rank pages — they cite sources. Here's what actually works for getting cited by ChatGPT, Perplexity, Claude, and Google AI Overview.
GPT-OSS-120b uses OpenAI's Harmony token protocol — analysis, commentary, and final channels. Here's how we handle CoT leakage and provider routing.
The best work happens when conversation stays continuous. Document-localized chat gives the workspace assistant richer context — here's how we architected it.
Benchmarking Liquid AI's LFM2.5-1.2B against LFM2-2.6B on a Pi 5 — the smaller model scores higher on IFEval (+9), runs 2.3x faster, and fits in under 1GB.
We built a Reasoner-Planner-Solver pipeline for a Pi 5 voice assistant, then replaced it with Instruct/Thinking model routing. Here's why simpler won.
Replacing Exa AI with self-hosted SearXNG and trafilatura on a Raspberry Pi — fully local web search in 2-3 seconds, no API keys, no data leaving the device.
Three tricks that took a 1.2B model's tool routing from 78% to 97% — renaming tools, adding a calibration line, and a regex post-processor.
One 1.2B model plays Reasoner, Planner, and Solver with different system prompts on a Raspberry Pi 5. Three LLM calls, 15-30 seconds for a reasoning task.
I kept adding regex patterns to fix edge cases until I realized I was overfitting a rule-based system — here's the framework for knowing when to stop
How I got multi-step reasoning working on a Raspberry Pi 5 with a 1.2B model — no thinking model needed. ReWOO cuts it to 2 LLM calls and 80% fewer tokens.
Stop writing massive Python files to tell your AI agents what they can do. We need a portable, plain-text standard for agent capabilities.
We want AI to work autonomously, but letting it write its own playbook creates a new kind of technical debt.