The Diligence Wall: Anthropic Shipped 10 Finance Agents Into the Carve-Out
On May 5, 2026, Anthropic shipped ten ready-to-run finance agents, Claude Opus 4.7, full Microsoft 365 add-ins, eight new data connectors, and a Moody's app covering 600 million companies. Eighteen days earlier, the Federal Reserve, FDIC, and OCC had quietly rescinded SR 11-7 and replaced it with SR 26-2, which carves generative and agentic AI explicitly out of model risk management. The launch landed into a regulatory architecture that, on paper, no longer applies to it.
That timing is not an accident. The shape of the carve-out is the shape of the product launch. And the question every model-risk and third-party-risk reviewer at every named partner bank is asking right now is the same question that broke the old framework: who validated this, against what control population, with what audit trail, and what happens when it gets a number wrong on something material?
This post is the answer I would write if you put the agents on my desk Monday morning. A 10-question Day 1 review checklist, plus the structural reading of why those questions are harder under SR 26-2 than they were under SR 11-7.
What Anthropic Actually Shipped
Ten templates in two clusters. Research and client coverage: pitch builder, meeting preparer, earnings reviewer, model builder, market researcher. Finance and operations: valuation reviewer, general ledger reconciler, month-end closer, statement auditor, KYC screener. Each runs as a Claude Cowork or Claude Code plugin, a Managed Agents cookbook, or a Microsoft 365 add-in.
Named launch users include Citadel, BNY, Carlyle, Mizuho, Travelers, Walleye, Hg, plus JPMorgan, Goldman Sachs, Citigroup, AIG, and Visa per Fortune's coverage. Eight new connectors join the existing roster (FactSet, S&P Capital IQ, MSCI, PitchBook, Morningstar, LSEG, Daloopa). Bloomberg is the conspicuous absence; they run their own LLM stack.
Two adjacent moves matter as much as the templates. On May 4, FIS announced an Anthropic-built Financial Crimes AI Agent piloting at BMO and Amalgamated, with credit decisioning, deposit retention, customer onboarding, and fraud prevention on the roadmap. Same day, Anthropic announced a $1.5B joint venture with Blackstone, Hellman & Friedman, Goldman, Apollo, General Atlantic, GIC, Leonard Green, and Sequoia to embed engineers in portfolio companies and redesign workflows around Claude. OpenAI announced a parallel JV the same day, per TechCrunch.
Anthropic is reporting 64.37% on the Vals AI Finance Agent benchmark for Opus 4.7. That number is vendor self-report and has not been third-party replicated. AIG's Peter Zaffino reportedly told Fortune that Claude scored 88% as accurate as a human expert on insurance claims. Also vendor-derived, also single-sourced.
What SR 26-2 Carved Out
SR 11-7 governed model risk management at large US banks for fifteen years. On April 17, 2026, the Federal Reserve, FDIC, and OCC jointly rescinded it and issued SR 26-2, which preserves the narrow model definition (statistical methods producing quantitative estimates) and adds three structural shifts.
Generative and agentic AI are explicitly out of scope. Direct quote from OCC Bulletin 2026-13: "Generative AI and agentic AI models are novel and rapidly evolving. As such, they are not within the scope of this guidance." The guidance is non-enforceable: "non-compliance with this guidance will not result in supervisory criticism." It is most relevant to banks above $30B in assets. The agencies committed to issue a separate AI-specific RFI; as of May 9, 2026, it has not landed.
FINOS framed the consequence: SR 11-7 "wrote itself out of the GenAI conversation." The 2011 framework was designed for systems "expressible in a few equations," and the agencies acknowledged the incompatibility by excluding the new category. Davis Polk's visual memo reads the same way: the new guidance hands agent governance back to the institution and tells it to apply broader risk management practices, undefined, with the RFI to follow at some unnamed future date.
Out-of-scope does not mean unregulated. Banks deploying generative and agentic AI still face fair lending law, Regulation B, FCRA, NYDFS Part 500, third-party risk standards (FRB SR 23-4 and OCC 2023-17), and a stack of state-level rules. What changed is the consolidation. SR 11-7 gave model-risk teams a single doctrine to point to. SR 26-2 replaces that with per-statute reasoning across half a dozen frameworks at once. That is the gap Anthropic shipped into: an eighteen-day window between regulatory clearance of the runway and ten templates landing on it.
The Tools-Versus-Models Counterargument
The strongest argument against the framing of this post is that the agents are not models in the SR 11-7 / SR 26-2 sense and were never meant to be governed there.
The Federal Reserve's model definition is "a complex quantitative method, system, or approach that applies statistical, economic, or financial theories to process input data into quantitative estimates." Agent templates orchestrate tool calls. They invoke calculators, retrieve data, compose prose, and surface results that a human signs. Under that read, an agent that drafts a pitch deck is no more a model than Word's autocomplete. If the agents are not models, they fall to third-party risk management, which has a clear playbook: SOC 2, security architecture review, data processing agreements, breach response, BCP, contract terms. A non-customer-facing deployment can clear in 4-6 weeks. The Kepler architecture pattern gives the cleanest version of this defense: "LLM for intent, deterministic code for retrieval and computation, every number traceable to source." The LLM does no quantitative estimation, the deterministic layer does, and the model definition does not bite.
Three problems with that read. First, pitch builder is hard to call a model; statement auditor and KYC screener are harder. Once an agent produces output that influences materiality decisions, the line between tool and model blurs. A KYC screener that filters 60% of cases and routes 40% to humans influences material outcomes regardless of how the firm classifies it. The HN thread's blunt version: "You can't get around HIPAA by saying 'lol wasn't me it was an Agent.'" Same logic applies to fair lending, AML, and sanctions screening.
Second, the FIS Financial Crimes Agent is plainly model-adjacent. Evaluating activity against known typologies and surfacing the highest-risk cases is a probability-assignment workload. AML and SAR-decisioning models have been SR 11-7-validated for over a decade. An agent doing the same work hits the model definition harder than a research-output template does. The fact that it ships through FIS does not change the underlying classification question.
Third, the carve-out is a temporary holding pattern, not a permanent grant. The agencies wrote SR 26-2 to defer, not to bless. Banks that build to "TPRM is enough because models are out of scope" will get re-validated when the RFI lands, on the agencies' timeline, not the bank's. Banks that build to a future MRM-equivalent standard will have lower re-validation cost. The carve-out rewards conservatism.
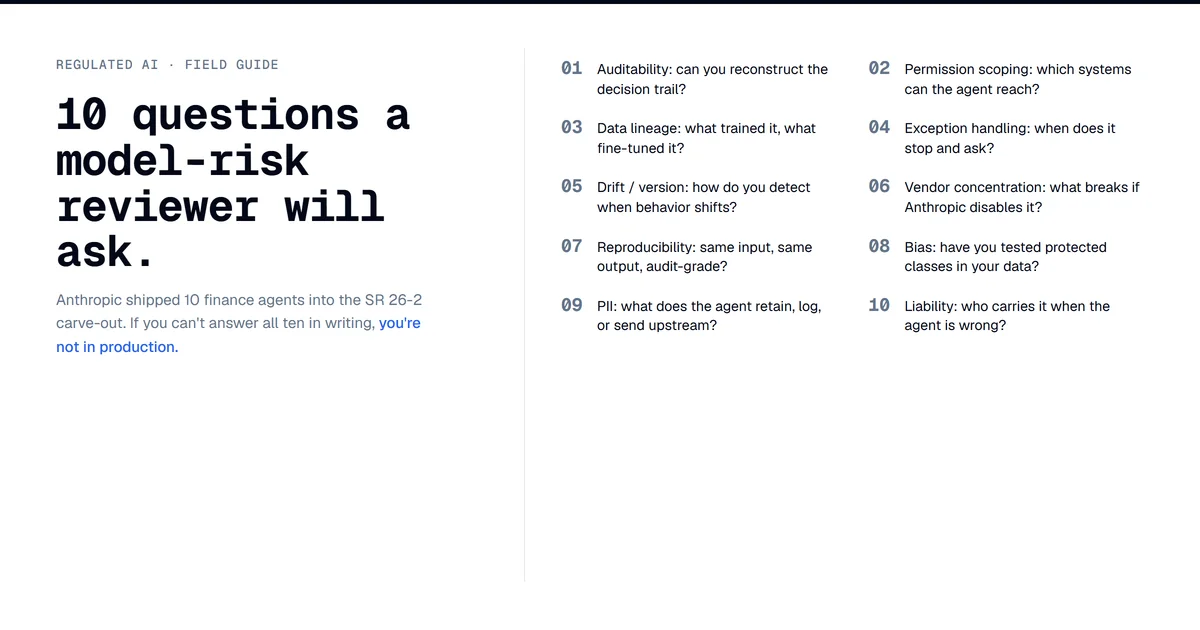
The 10-Question Day 1 Checklist
This is what a model-risk and third-party-risk function actually checks when an agentic AI vendor proposes deployment into a regulated workflow. None of these are exotic. All ten are standard today on traditional ML vendor diligence. SR 26-2's carve-out moves them from model-risk pre-flight to a third-party risk assessment that the bank now owns end-to-end.
-
Auditability. For every output, the agent must produce an audit trail that lets a non-technical examiner reconstruct which prompt, which model version, which tool calls, which data sources, in what order, with what intermediate state. The Claude Console audit log is a start. Can it export? Is it immutable? Is the log itself versioned? Can the same prompt with the same data deterministically re-run a year later for a regulator-driven re-test?
-
Permission scoping. Per-tool permissions are necessary, not sufficient. The model-risk question is whether the smallest tool-call set is enforced at the platform layer, not the prompt layer. Prompt-level boundaries are soft controls; a clever continuation can bypass them. Hard control means the credential the agent runs under cannot reach the broader system, period. IBS Intelligence reports the emerging standard is treating AI agents like privileged users, with separate access controls, observability, and rollback.
-
Data lineage. Every number that ends up in an artifact must trace back to a named source with timestamp, version, and access path. This is non-optional for any document a regulated bank issues. Connectors are the lineage substrate. The diligence question is whether the audit log records source attribution at the number level, not the document level. If a valuation reviewer agent quotes a P/E ratio that came from FactSet, can the bank prove FactSet's pricing-as-of timestamp made it into the artifact unchanged?
-
Exception handling. What happens when the agent encounters a case it cannot resolve? Traditional ML models route exceptions to human review through logged, named, scoped actions. Agents can hallucinate confidence, over-rely on a stale connector, or confidently draft a memo that misses the exception entirely. The IBS Intelligence read: "Cascading errors, where one incorrect AI decision triggers additional automated actions, remain a major concern. Confident hallucinations and weak audit trails." Cascade failure is the production failure mode that is genuinely new with agents. Single-shot models do not produce it.
-
Drift and version monitoring. Anthropic ships new model versions on a quarterly cadence. Opus 4.6 became 4.7 alongside the agent launch. The model the bank validated last quarter is not the model running this quarter unless the bank pins versions explicitly and Anthropic supports that contractually. How long does Anthropic commit to keeping a specific version available? What is the deprecation policy? What is the equivalence guarantee on a forced upgrade? SR 11-7 implicitly handled this because in-house models did not auto-upgrade. SR 26-2 does not address it because gen and agentic are out of scope.
-
Vendor concentration. If Claude Opus runs 80% of the FS agent layer in 18 months, the bank has a single vendor whose access list is gated by the executive branch (per the Mythos / Glasswing access regime, see the Mythos gate post), whose pricing has moved on capability rather than competitive pressure, and whose deprecation calendar is set by Anthropic's research roadmap. The vendor-concentration answer used to be SOC 2, tabletop, BCP. It now has to include geopolitical access regime as a first-order risk. SR 26-2 does not say the word "Glasswing."
-
Reproducibility. A model-risk reviewer expects to re-run a model against a control population and reproduce outputs. LLM agents are non-deterministic by default; temperature, sampling, tool-call order, model version, time-of-day load all change the output. Does Anthropic provide a deterministic-replay mode? Can the bank pin seed, temperature, and tool-call order for an audit re-run, with connector data pinned to original timestamps? Without deterministic replay, the validation playbook from SR 11-7 does not compose. Anthropic's launch materials do not describe a replay mode.
-
Bias and fairness. The launch agents avoid the cleanest fair-lending exposure by not making lending or claim-payout decisions directly. KYC screening, statement auditing, and valuation review still have fair-lending and disparate-impact ramps if the bank uses agent output as a filter on workflow distribution. Reg B's adverse-action rules do not go away because a generative model produced the recommendation. NYDFS Part 500's model-validation expectations do not go away because the model is multimodal. Fair-lending statistical testing still applies on any output that influences allocation. SR 26-2's silence on bias for agentic systems does not lower the statutory floor.
-
PII and data handling. Connectors give the agent read access to financial data partners' streams, sometimes write access into the bank's own systems. Where does data live during the agent run? How long is it retained? Who is the data processor? What is the breach notification chain? Agent templates make it easy to ship something that looks like a working app while bypassing the layer of security review that production deployment used to force. The diligence wall has to assume the easy path is the path most teams will take.
-
Liability allocation. The agents ship as templates the bank deploys, not as a hosted service Anthropic operates. Model and tooling are Anthropic's. Data is the bank's. The artifact reaches the regulator with the bank's name on it. SR 26-2 is silent on liability. That is the question SR 11-7 answered indirectly through the third-party-risk framework, which SR 26-2 keeps in scope but does not extend to agents. Liability allocation goes back to contract: SOW carve-outs, indemnification limits, error-rate SLAs the vendor will commit to. As of May 9, 2026, no such SLA is publicly named in Anthropic's enterprise terms.
What Model Risk Will Actually Check
Speaking generally from 13 years in financial services and current work in fraud strategy, none of those ten questions is exotic. They are the same intake review every traditional ML vendor has faced since 2014. What is different is that under SR 11-7, the bank had a single doctrine to point at when the vendor pushed back on any of them. Under SR 26-2, each question becomes a separate negotiation against a separate framework (FCRA, Reg B, NYDFS 500, SR 23-4, state rules), and the vendor can credibly argue that the agent is not a model and therefore the model-risk machinery does not apply. The pushback now lands harder on third-party risk and on the institution's own internal governance, neither of which is staffed for ten parallel high-stakes negotiations per quarter. That capacity gap is the diligence wall.
What Will Actually Move
Research, drafting, and reconciliation workflows where the artifact is intermediate and a human owns the output go to production fast. Pitch builder, meeting preparer, earnings reviewer, market researcher, model builder (in the sense of building draft analyst models), and valuation reviewer where a human signs. Six of the ten probably reach production at the named launch firms within six months. The diligence cost on these is tractable because nobody is filing the agent's output with a regulator.
Anything that touches a regulated decision moves slowly. Statement auditing where the artifact is what the bank submits. KYC screening where the output controls onboarding. Month-end close where the agent's number is the bank's reported number. Financial crimes investigation where the typology assessment drives the SAR filing. These four are the templates the wall is actually built for.
The path of fastest production deployment is the back door. The FIS Financial Crimes Agent reaches a regulated production surface the standalone templates cannot reach directly. Anthropic's forward-deployed engineers are embedded with FIS to co-design the agent and transfer knowledge so FIS can build additional agents independently. The bank is not buying an Anthropic product; it is buying a FIS product that uses Anthropic. Vendor risk concentrates on FIS, which already holds enterprise diligence relationships at every named bank. Roughly half of the top 100 banks globally run FIS somewhere in the stack.
The contested vendor field is not just Anthropic. Rogo raised a $160M Series D in early 2026 with 35,000+ professionals at 250+ institutions including Rothschild, Jefferies, Lazard, Moelis, and Nomura. Hebbia is enterprise-search-led with over 40% of the largest asset managers reportedly using it, and a sentence-level proof architecture that maps directly onto question 3 of the checklist. Sentence-level provenance is the data-lineage answer the diligence wall demands; the fact that Anthropic does not yet describe one publicly is the gap comparable vendors are already exploiting.
Cutover's analysis names the structural rule for orchestration-layer design: "no agent, automation or human has to mark its own homework." Independence of validation from execution is the principle the launch materials do not directly address, and the requirement the diligence checklist keeps circling back to.
The Twelve-Month Read
The agencies probably issue the AI RFI by Q1 2027. It will name agentic AI specifically and propose validation principles short of a full prescriptive framework. The FIS Financial Crimes Agent reaches general availability in H2 2026 and probably becomes the highest-deployment-volume Anthropic agent in regulated banking. Bloomberg launches a competing agent suite tied to the Terminal, widening Anthropic's data-partner gap to Bloomberg into a second front. One of the launch agents produces a publicly disclosed material error at a named firm within 12 months, because production deployment at this scale always produces one within 12 months, and the post-mortem becomes the case study every model-risk committee references for the rest of the decade.
This post connects to two prior arcs. The SR 11-7 overhaul piece was about how the framework was already failing the agent question before SR 26-2 made the failure official. The Mythos gate post was about how access to frontier models is now an executive-branch decision rather than a market decision. This post is about what happens when those two regimes meet at a bank's third-party-risk committee table, which is where the agents go through diligence in week three of every deployment.
The carve-out is a holding pattern. The product launch is a runway. The diligence checklist is the wall the runway runs into. Vendors that clear it earliest, through deterministic shadows, sentence-level provenance, or platform aggregation, win more of the production share than the sales-deck comparison suggests. Vendors that argue the wall does not apply to them get a different tour when the RFI lands.