The Unsupervised Agent Tax: What a 24/7 VM Subscription Actually Buys You
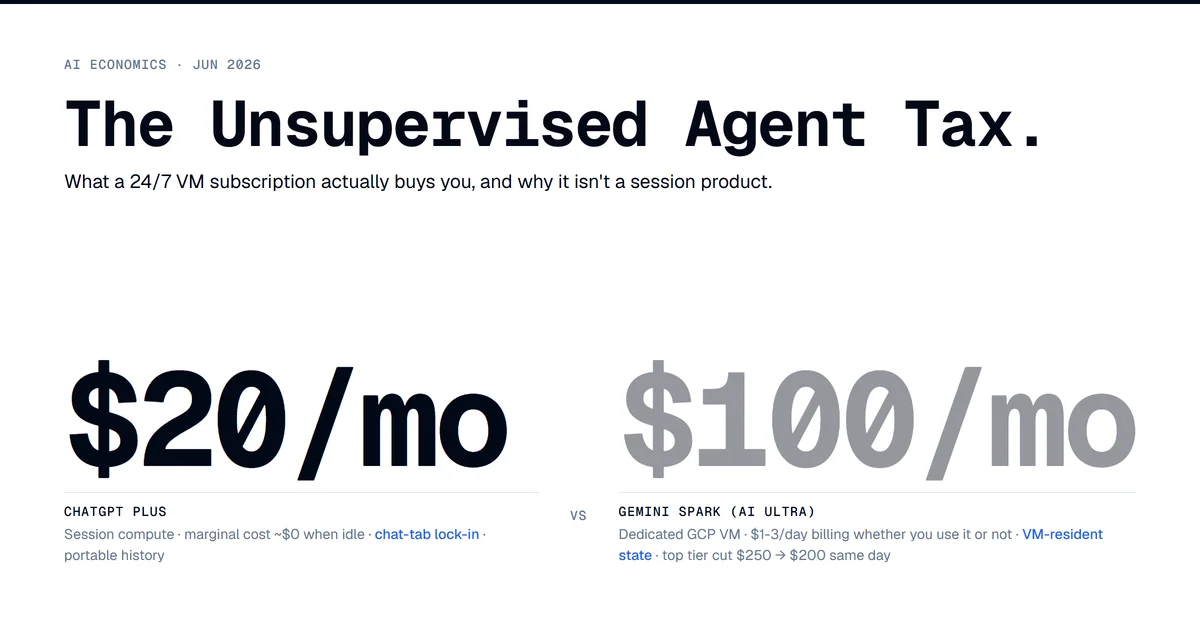
Gemini Spark runs on a dedicated Google Cloud VM whether your laptop is open or not. That single mechanic, announced at Google I/O on May 19 and rolled to AI Ultra subscribers a week later, is the part of the keynote that changes what a consumer AI subscription actually buys. ChatGPT Plus at $20 a month is a session product. Claude Pro at $20 is a session product. Spark at $100 is a VM-hour product. That's a different business pretending to be the same SKU.
The pricing tells you Google knows it. The same announcement introduced a new $100/month AI Ultra tier and cut the existing top tier from $250 to $200. The new tier opens a band the consumer AI market had structurally left empty, and the cut closes the gap to ChatGPT Pro at $200. Two simultaneous moves on the same announcement deck. Bundle YouTube Premium ($14/mo standalone) into the $100 tier and the effective AI cost is $86. Strip out the bundle and the underlying question gets sharper: what does a consumer pay $86 a month for when the model layer keeps getting cheaper?
The answer Spark is built around is persistence. Not better tokens. Not faster inference. A piece of compute that belongs to one user, runs whether they're logged in, and accumulates state across days. That's the consumer-side companion to the bifurcation thesis I wrote up in The Overtake Underneath. Anthropic took the enterprise floor; Google is trying to own the prosumer subscription before the agent layer commoditizes. The $100 tier is the price tag on that bet.
What Spark Actually Is
Pichai's keynote framing was deliberately careful. Spark is described as a personal AI agent that helps users navigate their digital life, taking action on their behalf and under their direction (TechCrunch). The operative phrase: 24/7 background operation so users don't need to keep a laptop open. Demos at I/O showed Spark drafting a status-update email from Gmail, Docs, and Sheets context. That was a directed task. The keynote did not show Spark scheduling itself a meeting next Tuesday on its own initiative.
That distinction matters. Spark is verified as an always-on, long-horizon harness running on dedicated cloud infrastructure. Spark is not verified as a self-directing agent that takes actions without user instruction. The unsupervised-VM mechanic is real. The standalone-initiative behavior is not yet demonstrated. Treat the agency claim as hedged until Google ships a demo that doesn't begin with a prompt.
The technical stack underneath: Gemini 3.5 plus a harness Google is calling Antigravity for long-horizon background tasks. Integration with Gmail, Docs, and Workspace at launch; third-party tools via MCP rolling out over the summer per Google's own product page. Rollout began with trusted testers during I/O week and expanded to US AI Ultra subscribers approximately a week later. There is no public adoption data yet. June 1 is too early for paid-conversion numbers.
What is verifiable, and what makes the rest of this post tractable, is the compute model. Each Spark instance runs on a dedicated Google Cloud VM. Server-side cost accrues regardless of whether the user touches the product. Everything else in this post follows from that one fact.
ChatGPT's Subscription Is Session Compute. Spark's Is Idle Compute.
A ChatGPT Plus subscription at $20/month is a metered prepay for inference cycles. When you don't use it, OpenAI's marginal cost on you is roughly zero. Storage, some idle infrastructure, but no GPU-time. Heavy users are partially subsidized by light users. The economics are similar to a gym membership: a small percentage who show up every day get more than they pay for, and the median subscriber pays for capacity they don't consume.
Spark at $100/month is the opposite shape. The VM is provisioned and billing whether the user is engaged or not. Google's marginal cost per subscriber per day is roughly the daily cost of a small dedicated VM on its own infrastructure, probably $1-3/day depending on shape and reserved-instance discounts. At a $100 price point with YouTube Premium ($14) and 20TB of storage (call it $10 standalone equivalent) bundled in, the AI portion has to underwrite $30-90/month of compute before you talk margin. Heavy users don't drive that number up much. Light users don't drive it down.
This inverts the usual consumer SaaS dynamic. The break-even on a Spark subscriber is not whether they use it enough to justify the price. It's whether the dedicated VM stays productive enough that the always-on cost amortizes against the perceived value of always-on behavior. Google is not selling tokens. It is selling residency, a piece of cloud that has your name on it whether you're looking or not.
For the consumer this changes the switching cost dramatically. Cancel ChatGPT Plus and you lose chat history; the friction is moderate. Cancel a Spark subscription that has been managing your inbox for three months and you lose continuity state, including the agent's accumulated context, its working memory, its ongoing background tasks. The structural feature is the lock-in geometry the VM creates, not the underlying model.
The $100 Wedge Sits in a Gap That Was Already Open
Pre-I/O pricing across the major labs looked like this:
| Tier | ChatGPT | Claude | Google AI |
|---|---|---|---|
| Entry | $20 (Plus) | $20 (Pro) | $20 (AI Pro) |
| Mid | none | $100-200 (Max) | none |
| Top | $200 (Pro) | none | $250 (AI Ultra) |
The $100 band was not empty by accident. It was empty because nobody had a product that obviously cost more than session-chat but obviously cost less than a $200 power-user tier. The prosumer who wanted more than $20 of Plus had to either jump four times to ChatGPT Pro at $200 or stay parked at the entry tier. Claude's $100-200 Max range was the closest thing to a mid-band, and the differentiation there was usage caps, not a structurally different product.
Spark fills that band with something the existing options don't have: a piece of always-on infrastructure. Per Google's own marketing positioning, the $100 tier targets developers, technical leads, knowledge workers, and advanced creators. That is exactly the prosumer segment paying $200 for ChatGPT Pro purely to get more inference headroom. Google is offering them a different capability shape (24/7 background tasks) for half the price. That's a sharper wedge than a cheaper version of the same thing.
The simultaneous cut at the top tier reads as defensive. $250 was the highest sticker price in the consumer AI market and the only one above ChatGPT Pro's $200. Cutting it to $200 brings Google into anchor parity with OpenAI on the high end while opening the new $100 mid-tier underneath. Two SKUs, two different competitive surfaces, one announcement.
What Google did not do is cut the entry-level AI Pro from $20. That's the band where most consumer AI subscriptions actually live, where ChatGPT Plus has 800M weekly active users feeding into ~50M paying subs. Going below $20 would have been the headline move if Google were trying to displace ChatGPT Plus directly. They aren't. They're trying to skip the entry tier and capture the band above it, the same band where Anthropic's enterprise revenue compounds. Consumer surface, prosumer price, agent harness.
Why Persistent Agents Lock Subscribers Differently
The thesis underneath the pricing is that a 24/7 agent creates retention that session-chat can't. Three mechanisms make this plausible.
Switching cost grows with accumulated context. A user who has spent three months pointing Spark at their Gmail, Docs, and calendar has a working memory that doesn't transfer to a competing agent. Migrating means rebuilding state. Compare to ChatGPT, where the underlying chat history is portable enough that power users routinely paste it across providers. VM-resident state is sticky in a way chat-tab state isn't.
Task latency expectations shift. Once a user expects the agent to handle inbox work overnight, the next time they open ChatGPT Plus to do a similar task and have to wait at the keyboard, the friction reads as a regression. The product category has been redefined under them. This is the same dynamic that made it hard to go back to Google after a year of Perplexity: not that the alternative is bad, but that the new behavior is the new baseline.
Subscriptions read as infrastructure once a daily task depends on them. Utility subscriptions get cut in budget reviews. Infrastructure subscriptions get protected. A user who treats Spark as the assistant managing their inbox is going to defend that line item the way they defend their cloud storage line item, by reflex, without re-evaluating whether they need it this month. ChatGPT Plus is closer to a tool. Spark is closer to a service.
None of these mechanisms have been proven at scale yet. Spark has been in the field for a week. The retention curves don't exist. What we can say is that Google built the product specifically for this hypothesis, priced it as if the hypothesis is true, and is willing to eat dedicated-VM cost per subscriber to test it. That's a meaningful signal even before the data arrives.
What Anthropic and OpenAI Could Do, and Why It's Harder Than It Looks
The obvious response is for OpenAI to ship a ChatGPT tier with always-on agent behavior. There are hints in this direction. The existing ChatGPT Tasks feature already does scheduled execution, and Sam Altman has talked about agent runtime as the next major product surface. But shipping a true VM-per-user model has cost implications OpenAI is structurally less ready to absorb than Google.
Google runs Spark on the same Google Cloud infrastructure that already serves enterprise workloads. The marginal cost of provisioning a small dedicated VM per consumer subscriber is real but bounded. Google effectively pays itself for the compute, and idle-VM economics scale with reserved-instance discounts and bin-packing across the fleet. OpenAI runs on Microsoft Azure under a commercial arrangement that exposes them to per-VM costs at closer-to-list rates. The same product shape costs more for OpenAI to build than it costs Google.
Anthropic is the more interesting case because there is no consumer-agent counter-move yet, and the company's revenue is ~80% enterprise per Sacra's tracker. The bifurcation thesis from the overtake post implies Anthropic doesn't need to ship a consumer agent at all. Its growth lever is enterprise-procurement compounding, and consumer is OpenAI's and (now) Google's surface to fight over. The likely Anthropic response is to keep doing what already works: ship enterprise agents into regulated workloads, let Claude Code keep eating developer mindshare, and let Google and OpenAI burn capital on the consumer-agent race. This is the strongest scenario for the bifurcation holding.
The weaker scenario, worth flagging because it would undermine this post's thesis, is Anthropic shipping a $100-ish Claude Pro-Plus tier with a Spark-equivalent harness in the back half of 2026. They have the model. They have the cloud relationships (AWS + GCP). The product gap is the harness and the consumer UX, both tractable on a 6-9 month timeline. If that ships, the bifurcation looks less like a structural split and more like a 12-month timing window. I'd give it roughly even odds by end of Q4. Happy to be wrong in either direction.
What This Means for Builders Watching the Consumer Surface
Three operational reads.
For consumer-AI product builders, the Spark mechanic is the new ceiling. If you're building a personal-assistant or background-task product on top of LLM APIs, your competitive surface just changed. Google is willing to provision a dedicated VM per user at $100/month. A wrapper-on-an-API product cannot match the persistence story Spark is offering unless it also provisions per-user compute. The math for venture-funded consumer AI startups got materially harder this month.
For prosumer subscribers doing the spend audit, the $100 Spark tier is rational if and only if you have workflows that benefit from background execution. If your AI usage is opening ChatGPT, having a conversation, then closing ChatGPT, you are paying for capacity you don't use. The product is built for users with inbox-management, document-drafting, or research-monitoring workflows that genuinely benefit from running overnight. For session-style users, Plus at $20 is still the right tier and the new $100 mid-band offers nothing.
For enterprise procurement leads looking at this through a procurement inversion lens, the consumer-agent push is mostly orthogonal to the regulated-workload story. Spark is a consumer product. The enterprise-agent question is still about Mythos clearance, Claude Code in dev environments, and the open-weight self-hosted path. What Spark changes for enterprise is the exec-team education surface. Leadership will see Spark in their personal lives within Q3 and start asking why corporate AI doesn't behave that way. The answer (regulated environments don't allow always-on autonomous compute over corporate inboxes) becomes harder to communicate when the consumer experience is normalizing the opposite.
The Cost Question Underneath
The Spark business model rests on a wager about compute economics that's worth naming directly. Google is betting that the cost of running a small dedicated VM per consumer subscriber will fall faster than the willingness-to-pay erodes. Gemini 3.5 Flash launched the same week at $1.50/M input, $9.00/M output, roughly 40% cheaper than 3.1 Pro. The model layer is compounding cheaper. The harness layer (Antigravity) is presumably running mostly on Flash for background tasks, not on the top-tier 3.5 Pro reserved for harder reasoning.
If Flash continues to compress at 40% per major release, the always-on-VM economics get materially better every two to three quarters. At some point the consumer can pay $50, then $30, then $20 for the same shape of product. That's the version of the future Google is building toward. It's also the version of the future where the $100 tier today looks expensive in retrospect, with early adopters paying for compute that subsidizes the cost curve.
The harder scenario for Google is the one where the model layer compresses but consumer willingness-to-pay for an always-on agent doesn't materialize at scale. In that scenario, Google has invested in a product surface that the market doesn't reward and the $100 tier becomes a smaller prosumer-niche SKU. No Spark adoption data exists yet that resolves this either way. June 1 is the wrong day to draw conclusions from.
What we can say is that the structural move has been made. Google has put consumer AI compute on its own balance sheet in a way OpenAI and Anthropic have not. The bet underneath the $100 sticker is that persistence beats session-chat as the product category. Six months from now we'll have retention curves. Eighteen months from now we'll know if Google was early or wrong.
I am running agent loops on my own hardware after work hours: Claude Code on a 4090, plus a couple of background scripts that wake up on cron and process inboxes and feeds. The Spark mechanic is the productized version of that homelab pattern, shipped to 900 million Gemini users at $100/month. Most of them won't want it. The ones who do are the ones whose subscription Google just made structurally harder to cancel.
The consumer surface of the bifurcation is becoming an infrastructure contest more than a price contest. Whoever owns the always-on compute owns the retention curve. That's the part of I/O worth watching.